OPID — AI Agent ที่ฝึกตัวเองได้ ไม่ต้องพึ่งครู ไม่ต้องมีสกิลเมโมรี

OPID — AI Agent ที่ฝึกตัวเองได้ ไม่ต้องพึ่งครู ไม่ต้องมีสกิลเมโมรี
ถ้าบอกว่า AI Agent สามารถเรียนรู้จาก “ประสบการณ์ของตัวเอง” โดยไม่ต้องมีคนสอน ไม่ต้องสร้างฐานข้อมูลสกิลแยก — ฟังดูเหมือน sci-fi เนอะ แต่ตอนนี้มันเริ่มเป็นจริงแล้ว OPID (On-Policy Skill Distillation for Agentic RL) คือระบบที่ทำให้ AI Agent ฝึกตัวเองจาก trajectory ที่มันเพิ่งเล่นจบไปหมาดๆ และดึงสกิลออกมาใช้ต่อได้เลย ไม่ต้องรอใครมาป้อนข้อมูล
TL;DR
- OPID คือวิธีฝึก AI Agent แบบ on-policy ที่ดึง skill supervision จาก trajectory ของตัวเอง
- ใช้ hierarchical skills สองระดับ: episode-level (แผนภาพรวม) + step-level (แต่ละขั้นตอน)
- ไม่ต้องใช้ external skill memory — ทุกอย่างอยู่ในตัว agent เลย
- ทดสอบบน ALFWorld, WebShop, Search-based QA แล้วเห็นผลชัดเรื่อง performance, sample efficiency, และ robustness
- ได้ 38 upvotes บน HuggingFace Daily Papers ⭐
- Paper: arxiv.org/abs/2606.26790
สารบัญ
- OPID คืออะไร?
- ปัญหาเดิมของ Reinforcement Learning
- OPID แก้ปัญหายังไง?
- Hierarchical Skills — สกิลสองชั้น
- ผลลัพธ์จากการทดสอบ
- ทำไม OPID ถึงสำคัญ?
- FAQ
OPID คืออะไร?
OPID ย่อมาจาก On-Policy Skill Distillation for Agentic RL เป็นผลงานวิจัยโดย Shuo Yang และคณะ ที่เสนอวิธีฝึก AI Agent ให้เรียนรู้จาก trajectory ของตัวเองแบบ on-policy
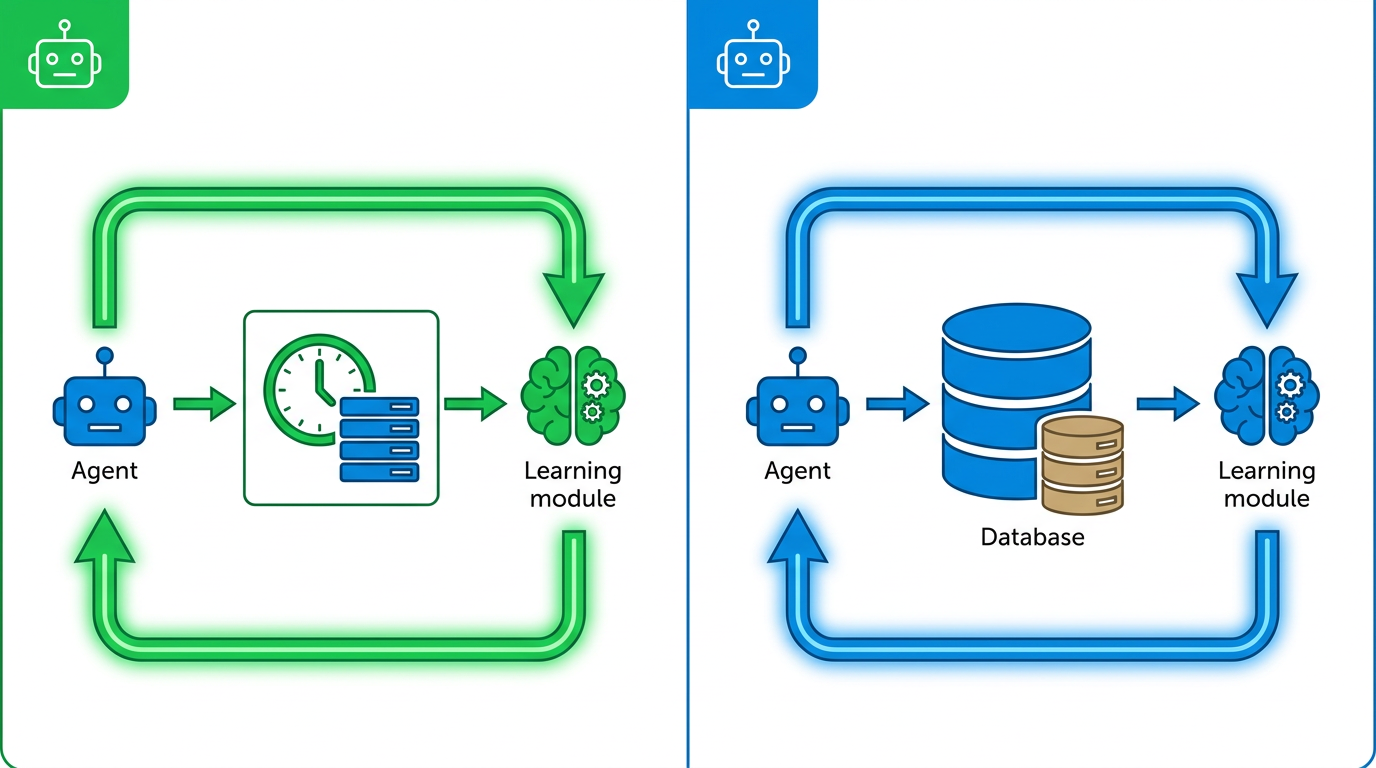
คำว่า “on-policy” ตรงนี้สำคัญมาก แปลว่า agent เรียนรู้จากสิ่งที่มัน “เพิ่งทำไป” จริงๆ ไม่ใช่จากข้อมูลเก่าที่สะสมไว้ มันเหมือนนักกีฬาที่ดูเทปตัวเองหลังแข่งจบแล้วปรับปรุงทันที ไม่ใช่ดูเทปของคนอื่น
สิ่งที่ทำให้ OPID น่าสนใจจนได้ 38 upvotes บน HuggingFace Daily Papers คือแนวคิดที่ว่า: เราไม่จำเป็นต้องสร้าง external skill memory แยกออกมาเลย ทุกอย่างที่ agent ต้องเรียนรู้ มันดึงออกมาจาก trajectory ของตัวเองได้หมด
ปัญหาเดิมของ Reinforcement Learning
ก่อนจะเข้าใจว่า OPID เจ๋งยังไง เรามาดูปัญหาเดิมๆ ของ Reinforcement Learning (RL) กันก่อน
Sparse Reward — รางวัลน้อย เรียนรู้ช้า
ปัญหาคลาสสิกของ RL คือ sparse reward คือ agent ต้องทำหลายขั้นตอนมากๆ กว่าจะได้รางวัลสักที สมมติ agent ต้องทำ 20 ขั้นตอนเพื่อสำเร็จภารกิจ แต่ละขั้นตอนไม่มี feedback อะไรเลย มันก็เหมือนคนเดินในห้องมืด ไม่รู้ว่าตัวเองเดินถูกทางหรือเปล่า
ต้องใช้ External Skill Memory
วิธีแก้ปัญหาก่อนหน้านี้คือการสร้าง external skill memory — ฐานข้อมูลสกิลที่แยกออกมาต่างหาก แล้วค่อยดึงมาใช้ตอนฝึก แต่ปัญหาคือ:
- ต้องสร้างและ maintain เพิ่มเติม
- Deployment ซับซ้อนขึ้น
- ข้อมูลใน skill memory อาจไม่ตรงกับสถานการณ์จริงของ agent
Deployment ยุ่งยาก
ระบบที่ต้องพึ่ง external components เยอะๆ จะ deploy ยากกว่า ต้องดูแลหลายส่วน ไหนจะเรื่อง latency ในการดึงข้อมูล ไหนจะเรื่อง synchronization — มันไม่ใช่แค่เขียนโมเดลแล้วจบ
OPID แก้ปัญหายังไง?
OPID เสนอแนวทางที่เรียบง่ายแต่ทรงพลัง: ดึง skill supervision จาก completed trajectories ของตัวเอง
ขั้นตอนหลักๆ มีดังนี้:
1. ทำภารกิจให้จบก่อน (Outcome-based RL)
Agent ทำภารกิจจนจบหนึ่งรอบ (episode) ไม่ว่าจะสำเร็จหรือล้มเหลว แล้วใช้ผลลัพธ์สุดท้าย (outcome) เป็นตัวกำกับการเรียนรู้ วิธีนี้เรียกว่า outcome-based RL — ไม่ต้องให้รางวัลทุกขั้นตอน แค่ดูว่าตอนจบได้ผลยังไง
2. ดึงสกิลจาก Trajectory
จาก trajectory ที่เพิ่งเล่นจบ OPID จะ distill สกิลออกมา 2 ระดับ:
- Episode-level skills: ภาพรวมว่า “ทำภารกิจนี้ต้องวางแผนยังไง”
- Step-level skills: รายละเอียดว่า “แต่ละขั้นตอนต้องทำอะไร”
3. Self-Distillation ระดับ Token
ขั้นตอนสุดท้ายคือ token-level self-distillation — agent ใช้สกิลที่ดึงออกมาได้มาฝึกตัวเองในระดับ token (หน่วยย่อยที่สุดของข้อความ) ทำให้การเรียนรู้แม่นยำขึ้น ไม่ใช่แค่จำภาพรวม แต่จำได้ถึงรายละเอียดปลีกย่อย
Hierarchical Skills — สกิลสองชั้น
จุดเด่นที่สุดของ OPID คือระบบ hierarchical skills ที่แบ่งสกิลออกเป็นสองชั้น:
Episode-Level Skills
เป็นแผนภาพรวมของภารกิจ คล้ายๆ กับ “สูตรอาหาร” — บอกว่าต้องเตรียมอะไร ลำดับขั้นตอนใหญ่ๆ เป็นยังไง เช่น “เดินไปห้องครัว → เปิดตู้เย็น → หยิบแอปเปิ้ล → วางบนโต๊ะ”
Step-Level Skills
เป็นรายละเอียดของแต่ละขั้นตอน คล้ายๆ กับ “เทคนิคการทำอาหาร” — จับมีดยังไง หั่นแบบไหน เวลาเท่าไหร่ เช่น “หันซ้าย 30 องศา → เดินตรง 5 ก้าว → ยื่นมือขวา → หยิบวัตถุ”
การแบ่งสองชั้นแบบนี้ทำให้ agent ทั้งเข้าใจภาพรวมและทำรายละเอียดได้ถูกต้อง เหมือนคนที่ทั้งรู้แผนและทำเป็น
ผลลัพธ์จากการทดสอบ
OPID ถูกทดสอบบน 3 benchmarks หลัก:
| Benchmark | ลักษณะงาน | ผลลัพธ์ |
|---|---|---|
| ALFWorld | ทำงานบ้านในบ้านจำลอง | ปรับปรุง performance ชัดเจน |
| WebShop | ช้อปปิงออนไลน์อัตโนมัติ | sample efficiency ดีขึ้น |
| Search-based QA | ค้นหาข้อมูลตอบคำถาม | robustness สูงขึ้น |

จุดที่น่าสนใจคือ OPID ไม่ได้แค่ทำให้ agent เก่งขึ้นในเรื่อง performance เท่านั้น แต่ยังทำให้เรียนรู้ได้เร็วขึ้น (sample efficiency) และทำงานได้คงที่กว่าเดิม (robustness) ด้วย ทั้งหมดนี้โดยไม่ต้องเพิ่ม external component ใดๆ
ทำไม OPID ถึงสำคัญ?
ไม่ต้องสร้าง External Skill Database
นี่คือจุดเปลี่ยนสำคัญเลย ระบบก่อนหน้านี้ต้องสร้าง skill database แยก ต้อง maintain ต้อง sync กับ agent — OPID ตัดขั้นตอนนี้ทิ้งหมด agent เรียนรู้จากตัวเอง ดึงสกิลจากตัวเอง ใช้จากตัวเอง
Deployment ง่ายขึ้น
เมื่อไม่มี external component ที่ต้องดูแล deployment ก็ง่ายขึ้นเยอะ ไม่ต้องกังวลเรื่อง latency ของ skill retrieval ไม่ต้องกังวลเรื่อง data pipeline แยกต่างหาก
AI Agent เก่งขึ้นเรื่อยๆ
เพราะ agent เรียนรู้จาก trajectory ของตัวเองแบบ on-policy ทุกครั้งที่มันทำภารกิจใหม่ มันก็ได้ข้อมูลใหม่มาฝึกตัวเอง ยิ่งทำมาก ยิ่งเก่งขึ้น — เหมือนคนที่เรียนรู้จากประสบการณ์จริง
ต่อยอดได้ง่าย
แนวคิด hierarchical skills + on-policy distillation สามารถนำไปประยุกต์กับ agent ในหลายๆ โดเมนได้ ไม่จำกัดแค่การทำงานบ้านหรือช้อปปิงออนไลน์
FAQ
On-Policy ต่างจาก Off-Policy ยังไง?
On-policy คือการเรียนรู้จากนโยบายปัจจุบันของ agent เอง — คือสิ่งที่มัน “เพิ่งทำไป” เปรียบเทียบกับ off-policy ที่เรียนรู้จากข้อมูลเก่าที่สะสมไว้ หรือจากนโยบายอื่น ข้อดีของ on-policy คือข้อมูลตรงกับสถานการณ์จริงที่ agent กำลังเผชิญ ทำให้เรียนรู้ได้แม่นยำกว่า แต่ก็แลกมากับต้องเก็บข้อมูลใหม่เรื่อยๆ
OPID ใช้ทำอะไรได้บ้าง?
OPID ถูกทดสอบกับงานหลายแบบ: การทำงานบ้านจำลอง (ALFWorld), การช้อปปิงออนไลน์อัตโนมัติ (WebShop), และการค้นหาข้อมูลตอบคำถาม (Search-based QA) แต่แนวคิดหลักของ OPID — คือการ distill สกิลจาก trajectory ของตัวเอง — สามารถนำไปประยุกต์กับ agent ในโดเมนอื่นๆ ได้ด้วย ไม่ว่าจะเป็น coding agent, data analysis agent หรือ agent ในสายงานอื่นๆ
มีโค้ดให้ลองไหม?
มี! โค้ดของ OPID เปิดให้ใช้งานบน GitHub ที่ github.com/jinyangwu/OPID ส่วน paper ฉบับเต็มอ่านได้ที่ arxiv.org/abs/2606.26790
Last updated: 2026-06-30 Source: OPID: On-Policy Skill Distillation for Agentic RL — Shuo Yang et al.